Univnet
Research for Vocoders
TTS (Text To Speech)
TTS can be viewed as a sequence-to-sequence mapping problem; from a sequence of discrete symbols (text) to a real-valued time series (speech signals). A typical TTS pipeline has two parts; 1) text analysis and 2) speech synthesis. The text analysis part typically includes a number of natural language processing (NLP) steps, such as sentence segmentation, word segmentation, text normalization, part-of-speech (POS) tagging, and grapheme-to-phoneme (G2P) conversion. It takes a word sequence as input and outputs a phoneme sequence with a variety of linguistic contexts. The speech synthesis part takes the context-dependent phoneme sequence as its input and outputs a synthesized speech waveform.
Wavenet
Wavenet V1
before wavenet, ther was two methods:
- generative method:
- which would produce the over all song of the sentece well, but would fail to produce the individual sounds well
- concatinative:
- we use a huge corpus of phonatics and concatinate them together to procude a whole sentence, this way we would procuce the individual sounds correctly, but we would lose the song of the sentence
wavenet:
tries to do both of the above methods, it also can change the speaker by changing some parameters
data output: 16 khz rate
we cant use normal RNN as the max seq length around 50
they used dilated CNNs:
- can have very long look back
- fast to train
WaveNet: is a deep generative model of audio data that operates directly at the waveform level. WaveNets are autoregressive and combine causal filters with dilated convolutions to allow their receptive fields to grow exponentially with depth, which is important to model the long-range temporal dependencies in audio signals.WaveNets can be conditioned on other inputs in a global (e.g. speaker identity) or local way (e.g. linguistic features). When applied to TTS, WaveNets produced samples that outperform the current best TTS systems in subjective naturalness. Finally, WaveNets showed very promising results when applied to music audio modeling and speech recognition.
Wavenet V2
The original Wavenet implementation suffered from low speed inference, because it predicts samples squentially. They needed to predict time samples in prallel so that wavenet can be used in production, so the used a fully trained wavenet teacher, to train a smaller wavnet student, which doesn’t depend on previous samples to produce the current sample, while still maintaining the same quality.
WaveGan
WaveGAN is a generative adversarial network for unsupervised synthesis of raw-waveform audio (as opposed to image-like spectrograms).
The WaveGAN architecture is based off DCGAN. The DCGAN generator uses the transposed convolution operation to iteratively upsample low-resolution feature maps into a high-resolution image. WaveGAN modifies this transposed convolution operation to widen its receptive field, using a longer one-dimensional filters of length 25 instead of two-dimensional filters of size 5x5, and upsampling by a factor of 4 instead of 2 at each layer. The discriminator is modified in a similar way, using length-25 filters in one dimension and increasing stride from 2 to 4. These changes result in WaveGAN having the same number of parameters, numerical operations, and output dimensionality as DCGAN
Before WaveGan
Autoregressive generation:
- It’s an approach in which speech samples are generated one by one in sequence.
- Examples: WaveNet
- Has high quality
- Takes around 180 secs to generate a one second of speech
- can’t be applied to services in production due to low speed
Non-autoregressive generation:
- It’s an approach where all voice samples are generated in prallel
- Examples: Prallel WaveNet
- Lower quality than autoregressive method
- takes 0.03 seconds to generates one second of speed
End-to-End TTS
End-to-end TTS systems can be splitted into two main components:
- Speech Synthesizer, which takes in raw text and output mel-spectrogram.
- Ex: Tacotron
- Vocoder, which takes in mel-spectrogram and outputs sound waves.
- Ex: Prallel WaveGan, Univnet
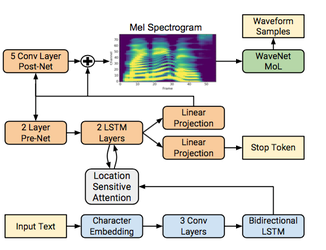
Tacotron2
Tacotron 2 is a neural network architecture for speech synthesis directly from text. It consists of two components: a recurrent sequence-to-sequence feature prediction network with attention which predicts a sequence of mel spectrogram frames from an input character sequence, followed by a modified WaveNet model acting as a vocoder to synthesize time-domain waveforms from those spectrograms.
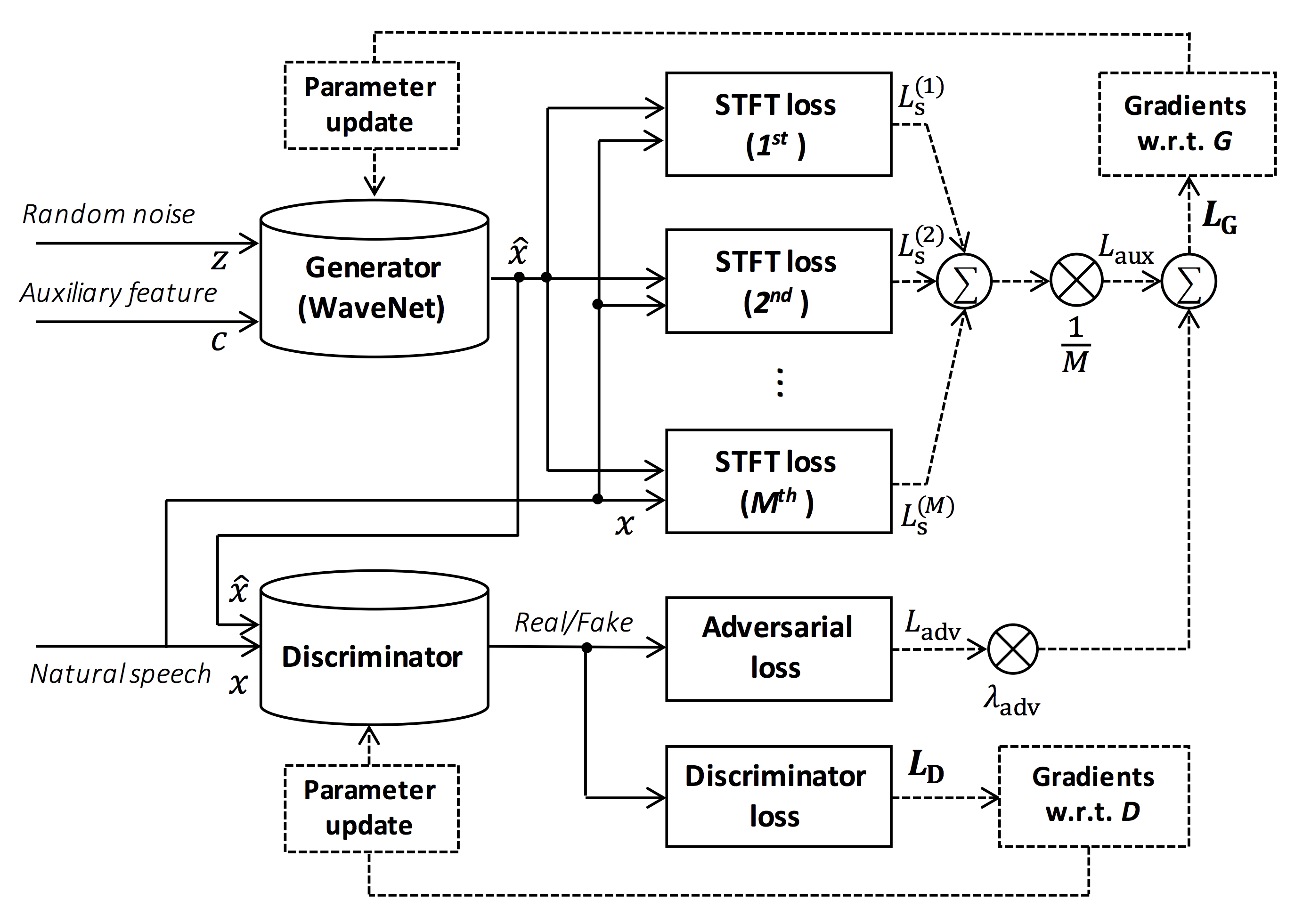
Prallel WaveGan
Parallel WaveGAN1, a distillation-free, fast, and small-footprint waveform generation method using a generative adversarial network. In the proposed method, a non-autoregressive WaveNet is trained by jointly optimizing multi-resolution spectrogram and adversarial loss functions, which can effectively capture the time-frequency distribution of the realistic speech waveform. As our method does not require density distillation used in the conventional teacher-student framework, the entire model can be easily trained even with a small number of parameters. In particular, the proposed Parallel WaveGAN has only 1.44 M parameters and can generate 24 kHz speech waveform 28.68 times faster than real-time on a single GPU environment. Perceptual listening test results verify that our proposed method achieves 4.16 mean opinion score within a Transformer-based text-to-speech framework, which is comparative to the best distillation-based Parallel WaveNet system.
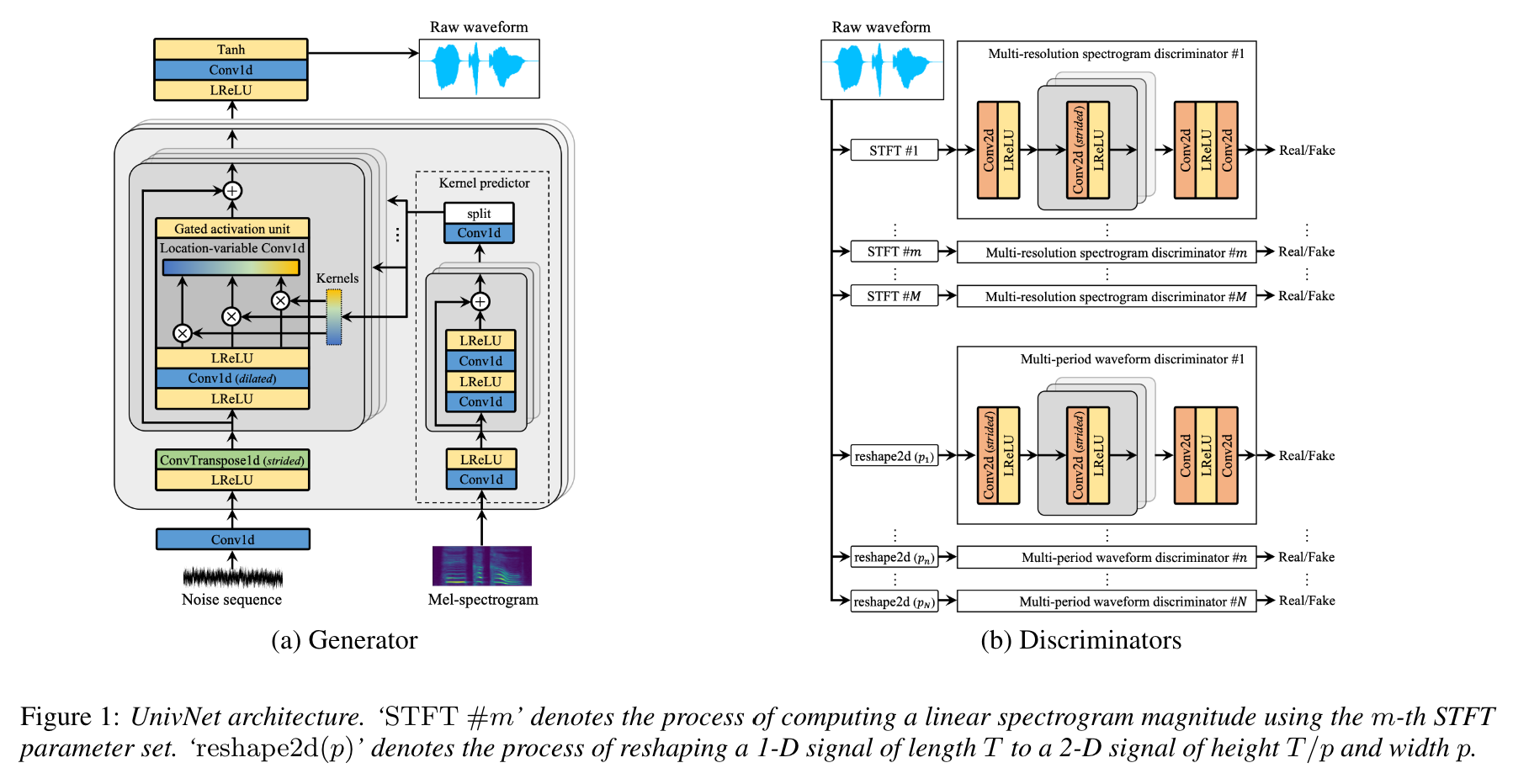
Univnet
UnivNet, a neural vocoder that synthesizes high-fidelity waveforms in real time. Inspired by works in the field of voice activity detection, we added a multiresolution spectrogram discriminator that employs multiple linear spectrogram magnitudes computed using various parameter sets. Using full-band mel-spectrograms as input, we expect to generate high-resolution signals by adding a discriminator that employs spectrograms of multiple resolutions as the input
Resources
- Wavenet
- WaveGan
- Prallel WaveGan
- https://www.youtube.com/watch?v=knzT7M6qsl0
- https://github.com/kan-bayashi/ParallelWaveGAN
- https://arxiv.org/pdf/1910.11480.pdf
- Tacotron